






Att på förhand identifiera individer med framtida stort vårdbehov kan bidra till klokare användning av begränsade sjukvårdsresurser. Prediktionsmetoderna bör vara administrativt enkla och helst använda redan registrerade parametrar.
Vår prediktiva modell bygger på användning av ACG-systemet (adjusted clinical groups: ett sammanvägt mått av diagnoser, ålder och kön).
Modellen kan generera en lista per vårdcentral med de individer modellen identifierar vara i riskzon för stort framtida behov av sjukvård.
Vårdcentralerna ges möjlighet att optimera vården av dessa patienter med målsättningen att minska totalt vårdbehov och/eller erbjuda vård på rätt instans och bättre livskvalitet.
Vårdcentralerna får även möjlighet att fördela sina resurser jämnt för att möta dessa individers behov av sjukvård.
Prediktiva verktyg för att kunna identifiera individer med stort framtida vårdbehov kan bidra till klokare användning av begränsade sjukvårdsresurser. I primärvården finns patienter med stor multisjuklighet och många svårmätta dimensioner, vilket gör det svårt att mäta sjuklighet och behov.
Västra Götalandsregionen har sedan vårdvalet för primärvård genomfördes 2009 använt ACG-systemet (adjusted clinical groups) som grund för en del av ersättningen till vårdcentralerna [1]. ACG är framtaget som ett beskrivningssystem för hela sjukvården, där hänsyn tas till sjuklighet, ålder och kön. ACG försöker beskriva sjukligheten i likvärdiga grupper avseende utnyttjande av sjukvårdsresurser. Varje patient hänförs till en ACG-grupp (en patient – en ACG) beroende av sjuklighet, ålder och kön. Varje ACG-grupp tilldelas en vikt som beskriver ACG-gruppens sjukvårdsresursutnyttjande i förhållande till de andra ACG-grupperna.
Redan tidigt i utvecklingen av ACG har resursfördelningsaspekten lyfts in för att kunna styra och fördela resurserna i vården utifrån sjuklighet. Det är alltså möjligt att se hur olika sjuklighet kan ta jämförbara sjukvårdsresurser i anspråk.
I Västra Götalandsregionen bygger ACG i löpande drift på primärvårdsdiagnoser och kostnader för primärvård, vilket gör att systemet speglar sjuklighet och resursbehov ur ett primärvårdsperspektiv. En kraftig ökning av antalet registrerade diagnoser har noterats i Västra Götalandsregionen sedan starten av vårdvalet 2009. Sedan ett halvår har ökningen avstannat, och mängden registrerade diagnoser ligger på en stabil nivå. Detta är i linje med de erfarenheter man har vid Johns Hopkins University från ACG-implementering runt om i världen [Chad Abrams, Johns Hopkins University, Baltimore, pers medd; 2014].
Målet – att få fram en lista
Med en stabil diagnoskodning kan Västra Götalandsregionen nu börja använda de prediktionsmodeller som ingår i ACG-systemet. Att bygga prediktionsmodeller för primärvård med goda förklaringsvärden utifrån kända data, såsom tidigare resursutnyttjande och demografi, är relativt väl underbyggt i litteraturen [2, 3].
Målsättningen med arbetet är att skapa en modell som i praktiken ger en lista till varje vårdcentralchef över de 70–200 individer som har högst risk för stort resursbehov i primärvården de kommande 12 månaderna. Syftet är tvåfaldigt: dels att säkerställa att dessa patienter verkligen är identifierade av vårdcentralerna, dels att visa på dessa patienters fördelning mellan läkarna på vårdcentralen. Därmed förbättras möjligheten för patienten att få vård och för vårdcentralen att ge läkarna en rimlig arbetsbelastning.
Metod
I ACG-systemet finns flera inbyggda funktioner för att spegla patienters sjukvårdsresursbehov. ACG-mjukvaran delar automatiskt in patienter i sex större sjukdomskategorier kallade resource utilization band (RUB) [1]. De sex kategorierna består av ACG-grupper som beskriver samma sjukdomsbörda. De sex kategorierna är:
- 0 – icke användare
- 1 – friska användare
- 2 – låg sjuklighet
- 3 – måttlig sjuklighet
- 4 – hög sjuklighet
- 5 – mycket hög sjuklighet.
RUB-kategorierna är inte lika stora. RUB 5 är den till antalet patienter minsta, eftersom den innefattar de allra sjukaste patienterna; i Västra Götalandsregionens fall de allra sjukaste i ett primärvårdsperspektiv.
Säkerheten i att RUB 5 verkligen pekar ut patienterna med störst sjukvårdsbehov är naturligtvis beroende av storleken på populationen. För individidentifierande sammanställningar är det inte tillåtet att blanda data från flera vårdgivare (huvudmän). En enskild vårdcentral får därmed ett mindre underlag med sina listade patienter än en vårdcentral som ingår i en koncern eller förvaltning med många andra vårdcentraler.
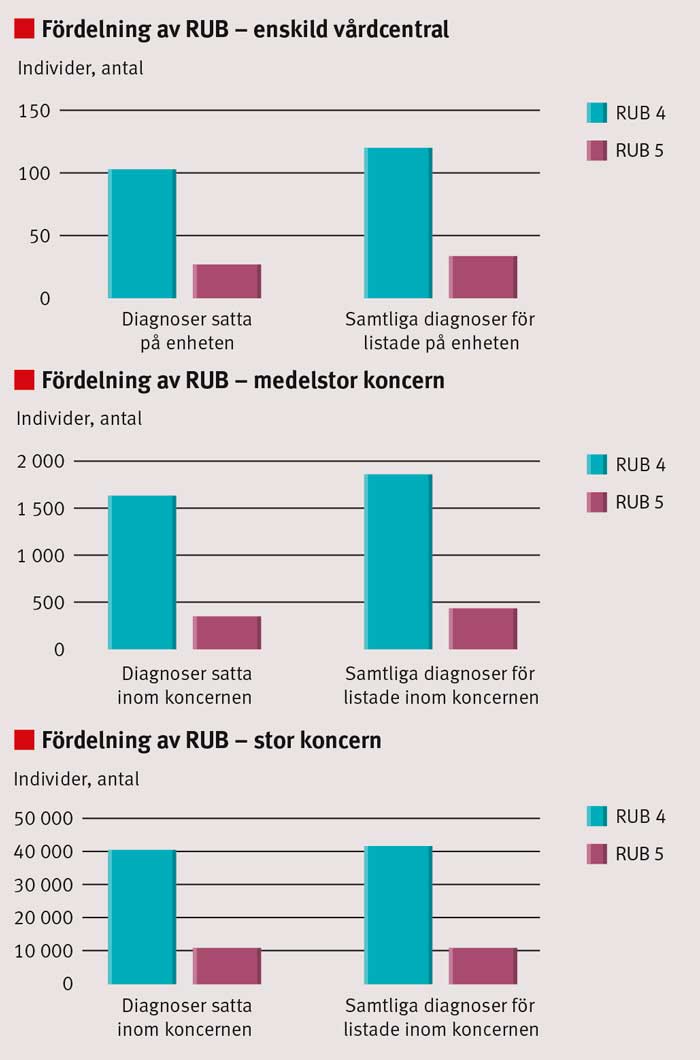
För att bedöma betydelsen av detta har vi undersökt hur stor skillnaden blir om vi tittar på de listade patienterna hos huvudmän av olika storlek, om RUB-fördelningen enbart baseras på diagnoser satta inom respektive enhet eller vårdgivare eller på alla primärvårdsdiagnoser oavsett vilken primärvårdsenhet eller huvudman de är satta på (i det sistnämnda fallet kan individidentifierande listor inte skapas av juridiska skäl). Jämförelse görs för en enskild vårdcentral som inte ingår i någon koncern, för en medelstor koncern med 10 vårdcentraler och en stor koncern med >100 vårdcentraler.
Det finns en prediktiv modell inbyggd i ACG-systemet, som bygger på dess ingående komponenter, i vårt fall primärvårdskostnader, diagnoser, ålder och kön. Med hjälp av dessa fastställs ett riskmått för hög totalkostnad (probability high total cost) som ska spegla patienter med >50 procents risk att tillhöra de 5 procent av patienterna med högst kostnad under kommande 12 månader. För att uppnå en så säker prediktion av framtida resursbehov hos enskilda individer som möjligt kombinerar vi RUB kategori 5 och riskmåttet för hög totalkostnad. Individer som identifieras via ettdera av de två måtten eller bägge i kombination klassificeras i vår modell som högriskindivider för stort sjukvårdsutnyttjande.
Modellen har testats mot historiska data under 1 januari 2013 till 31 december 2013. Som mått på framtida och aktuella resursbehov studeras hur stor andel av befolkningen i Västra Götaland som har gjort >19 besök någonstans i vården under den studerade tidsperioden samt hur stor andel som har varit inskriven vid sjukhus >2 gånger under den studerade tidsperioden. Med besök avses fysiskt besök hos någon personalkategori i såväl primärvård som specialiserad vård.
Resultat
Av 1 603 357 invånare i Västra Götaland gjorde 89 460 individer (5,6 procent) >19 besök i vården under 2013, och 18 608 individer (1,2 procent) var inskrivna på sjukhus >2 gånger.
Med den beskrivna prediktiva modellen identifierades 24 037 individer, 1,5 procent av befolkningen, med hög risk för stort framtida sjukvårdsutnyttjande. Av dessa gjorde 6 180 (25,7 procent) >19 besök i vården under 2013, och 2 780 (11,6 procent) var inskrivna på sjukhus >2 gånger under samma tidsperiod. Den prediktiva modellen lyckades således identifiera riskpatienter med hög specificitet men låg sensitivitet på grund av det urval som gjordes (Tabell I).
Eftersom modellens möjlighet att predicera beror på grundpopulationens storlek, fann vi att den stora koncernen, med störst bakomliggande population, skiljer sig minst mellan om enbart diagnoser satta inom samma huvudman används eller om alla primärvårdsdiagnoser för de listade patienterna tas med oavsett om de är satta på en enhet hos huvudmannen eller på en enhet med annan huvudman (Tabell II). Skillnaden för RUB 5 hos enskild vårdcentral är 21 procent, hos medelstor koncern 26 procent och hos stor koncern 3 procent (Figur 1).
Diskussion
Vi bedömer att vi med denna modell med tillräcklig precision kan identifiera individer med hög risk för framtida (inom 12 månader) stort sjukvårdsbehov. Detta ger vårdcentraler möjlighet att arbeta aktivt med dessa individer för att optimera deras vård och omhändertagande i syfte att minska sjukvårdsbehovet och förbättra livskvaliteten.
Skillnaden i antalet identifierade patienter med RUB 4–5, beroende på om enbart diagnoser satta inom samma huvudman eller om alla primärvårdsdiagnoser hos alla huvudmän användes, är mycket liten mellan medelstor koncern och enskild vårdcentral (Figur 1), vilket är förvånande. Möjligen kan valet av enskild vårdcentral respektive medelstor koncern spela roll. Den medelstora koncernen bedriver sina verksamheter på geografiskt skilda platser och med hög grad av självstyre, vilket kan göra att bilden blir ganska likvärdig med den enskilda vårdcentralen. Dessutom är de absoluta talen små, varför enskilda individer spelar en större roll för dessa två varianter på urval. Vår bedömning är att en variation på drygt 20 procent är acceptabel för att kunna använda även enskilda vårdcentralers patientunderlag. Dock är det så att ju större underlag som RUB-klassificeringen bygger på, desto mindre variation och större sannolikhet att rätt patienter identifieras.
I den stora koncernen kan det bli klustereffekter, eftersom det är osannolikt att sjukligheten är helt jämnt fördelad mellan vårdcentralerna. Detta innebär att en del vårdcentraler kommer att få fler av sina listade patienter markerade som riskpatienter, medan andra får färre.
Det finns naturligtvis en etisk aspekt som måste tas i beaktande. I en primärvård med begränsade resurser kan inte alla individers samtliga upplevda sjukvårdsbehov tillgodoses. I Socialstyrelsens rapport »Prioriteringar i hälso- och sjukvården« finns prioriteringsgrupp 1–4 redovisade [4]. I prioriteringsgrupp 1, som bör prioriteras högst, återfinns bl a vård av kroniska sjukdomar samt flera andra tillstånd. Ju mer komplicerad multisjuklighet en individ har, desto större sannolikhet att hen flaggas ut som högriskindivid för stort framtida sjukvårdsbehov.
Kan vara del av vårdcentralernas prioriteringsarbete
Vår modell kan vara en del av vårdcentralernas prioriteringsarbete, särskilt som den inte kräver manuellt extra arbete, utan bygger på redan registrerade data. För den enskilda individen innebär den prediktiva modellen att man kan bli utpekad som en individ med stor sjuklighet och stor risk för framtida behov av sjukvård jämfört med andra. Algoritmen i den prediktiva modellen bygger på för alla parter kända fakta, såsom ålder, kön och kända sjukdomar. Målet och vinsten är desamma för både individen och vårdcentralen: att finna dessa individer med stor sjuklighet och optimera vården av dem.
Vårdcentralerna behöver utveckla metoder för hur de ska närma sig dessa patienter och noga poängtera att kontakt tas för att förbättra deras hälsa och minska effekterna av olika sjukdomar.
Bättre än journalgenomgångar och fokuspatientgrupper
Norrbottens läns landsting genomförde under 2013 en kartläggning, vilken har föredragits för det av Sveriges Kommuner och landsting sammankallande nationella ACG-nätverket [Inga-Britt Stenman, Norrbottens läns landsting, Luleå, pers medd; 2013]. Slutsatsen av kartläggningen var att RUB identifierade de mest sjuka lika bra som, och i viss mån bättre än, det manuella arbetssätt med journalgenomgång och fokuspatientgrupper som man tidigare tillämpat.
I denna kartläggning fann man inga indikationer från patienterna att de misstyckte, kände sig kränkta eller övervakade på ett otillbörligt sätt.
Denna prediktiva modell kan bli ett verktyg för primärvården i arbetet med de mest vårdkrävande patienterna utan att fordra nya administrativa arbetsinsatser för verksamheten. Vi planerar nu ett test på 10 vårdcentraler i Västra Götalandsregionen för att se om modellen ska introduceras i hela regionen.
Potentiella bindningar eller jävsförhållanden: Inga uppgivna.
Referenser
- The Johns Hopkins ACG system. http://acg.jhsph.org/
- Gao J, Moran E, Li YF, et al. Predicting potentially avoidable hospitalizations. Med Care. 2014;52(2):164-71.
- Hippisley-Cox J, Coupland C. Predicting risk of emergency admission to hospital using primary care data: derivation and validation of QAdmissions score. BMJ Open. 2013;3(8):e003482.
- Prioriteringar i hälso- och sjukvården. Socialstyrelsens analys och slutsatser utifrån rapporten »Vårdens alltför svåra val?«. Stockholm: Socialstyrelsen; 2007. Artikelnr 2007-103-4.
Summary
We describe a method, which uses already existent administrative data to identify individuals with a high risk of a large need of healthcare in the coming year. The model is based on the ACG (Adjusted Clinical Groups) system to identify the high-risk patients. We have set up a model where we combine the ACG system stratification analysis tool RUB (Resource Utilization Band) and Probability High Total Cost >0.5. We tested the method with historical data, using 2 endpoints, either >19 physical visits anywhere in the healthcare system in the coming 12 months or more than 2 hospital admissions in the coming 12 months. In the region of Västra Götaland with 1.6 million inhabitants, 5.6% of the population had >19 physical visits during a 12 month period and 1.2% more than 2 hospital admissions. Our model identified approximately 24 000 individuals of whom 25.7% had >19 physical visits and 11.6% had more than 2 hospital admissions in the coming 12 months. We now plan a small test in ten primary care centers to evaluate if the model should be introduced in the entire Västra Götaland region.


















